


triton inference server
GitHub:triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge inferencing solution. (github.com)
官方镜像仓库:Triton Inference Server | NVIDIA NGC
Triton Inference Server 是一个开源的深度学习推理服务器,由 NVIDIA 开发。它能够为深度学习模型提供高性能的推理服务,支持多种框架和硬件平台,并且具有灵活的部署选项。
Triton Inference Server 支持常见的深度学习框架,包括 TensorFlow、PyTorch、ONNX 等,可以在 GPU、CPU 和其他加速器上进行推理。它还提供了灵活的部署选项,可以在单个节点或集群中进行部署,并支持自动扩展和负载均衡。
该推理服务器还具有高性能和低延迟的特点,可以处理大规模的并发请求,并且能够实现快速的模型加载和推理。此外,Triton Inference Server 还提供了监控和管理工具,方便用户对模型进行管理和监控。
docker 启动 triton 服务
这里使用的 trion 的最新版本 24.05-py3
# 拉取docker镜像
docker pull nvcr.io/nvidia/tritonserver:24.05-py3
triton 依赖模型仓库的概念集中管理多版本、多模型,官方概念如下:
The [model repository](https://github.com/triton-inference-server/server/blob/main/docs/user_guide/model_repository.md) is the directory where you place the models that you want Triton to serve. An example model repository is included in the [docs/examples/model_repository](https://github.com/triton-inference-server/server/blob/main/docs/examples/model_repository). Before using the repository, you must fetch any missing model definition files from their public model zoos via the provided script.
Triton 是 NVIDIA 开发的一个高效的推理服务器,用于部署和管理 AI 模型。创建一个结构合理的 Triton 模型仓库(Model Repository)是确保模型部署和管理顺利进行的重要步骤。以下是一个标准的 Triton 模型仓库的结构示例:
- 仓库根目录:包含所有模型的顶层目录。
- 模型目录:每个模型都有一个独立的目录,目录名即为模型名。
- 版本目录:每个模型目录下可以有一个或多个版本目录,每个版本目录名为具体的版本号。
- 配置文件:每个模型目录下有一个
config.pbtxt文件,用于定义模型的配置。
以下是具体的目录结构示例:
model_repository/
├── model_a/
│ ├── 1/
│ │ └── some_other_file
│ │ ├── model.pt
├── model_b/
│ ├── 1/
│ │ ├── model.onnx
│ ├── config.pbtxt
├── model_c/
│ ├── 1/
│ │ ├── model.savedmodel
│ ├── config.pbtxt
具体说明
- model_repository:这是模型仓库的根目录,可以根据实际需要命名。
- model_a、model_b、model_c:这些是模型目录,每个模型有自己的目录,目录名即模型名。在这个例子中,
model_a是一个 PyTorch 模型,model_b是一个 ONNX 模型,model_c是一个 TensorFlow SavedModel 模型。 - 版本目录(如 1、2):每个模型目录下有一个或多个版本目录,目录名是模型的具体版本号。这允许同时管理和部署多个版本的同一个模型。在每个版本目录下,存放具体的模型文件,如
model.pt、model.onnx、model.savedmodel等。 - 配置文件(config.pbtxt):每个模型目录下有一个配置文件,
config.pbtxt,用于定义模型的配置信息,如输入输出的名称和数据类型,最大批处理大小,优化设置等。
示例配置文件(config.pbtxt)
以下是一个简单的 config.pbtxt 示例:
name: "model_a"
platform: "pytorch_libtorch"
max_batch_size: 8
input [
{
name: "input__0"
data_type: TYPE_FP32
dims: [3, 224, 224]
}
]
output [
{
name: "output__0"
data_type: TYPE_FP32
dims: [1000]
}
]
这个配置文件定义了名为 model_a 的 PyTorch 模型,最大批处理大小为 8,输入张量的名称为 input__0,数据类型为 TYPE_FP32,维度为 [3, 224, 224],输出张量的名称为 output__0,数据类型为 TYPE_FP32,维度为 [1000]。
通过这种结构设计和配置,可以确保 Triton 推理服务器能够正确加载和管理模型,并根据配置文件进行推理服务。
支持的 platform 和 backend
下面是 platform 和 backend 支持情况的表格形式:
| 平台(Platform) | 描述 |
|---|---|
tensorflow_graphdef |
加载 TensorFlow GraphDef 格式的模型 |
tensorflow_savedmodel |
加载 TensorFlow SavedModel 格式的模型 |
tensorrt_plan |
加载 TensorRT 的计划(plan)文件 |
pytorch_libtorch |
加载 PyTorch JIT 格式的模型 |
onnxruntime_onnx |
加载 ONNX 格式的模型 |
openvino |
加载 OpenVINO 格式的模型 |
python |
加载 Python 解释器的模型,通常用于自定义的 Python 脚本 |
dali |
加载 NVIDIA DALI(Data Loading Library)的模型 |
| 后端(Backend) | 描述 |
|---|---|
tensorflow |
运行 TensorFlow 模型 |
tensorrt |
运行 TensorRT 模型 |
libtorch |
运行 PyTorch 模型 |
onnxruntime |
运行 ONNX 模型 |
openvino |
运行 OpenVINO 模型 |
python |
运行 Python 脚本的模型 |
dali |
运行 DALI 模型 |
启动镜像使用 docker-componse 执行
version: "3.9"
services:
TritonInferenceServer:
image: nvcr.io/nvidia/tritonserver:24.05-py3
container_name: TritonInferenceServer
ports:
- "8000:8000"
- "8001:8001"
- "8002:8002"
volumes:
- ${PWD}/model_repository:/models
command: ["tritonserver", "--model-repository=/models"]
# 使用gpu
deploy:
resources:
reservations:
devices:
- driver: "nvidia"
device_ids: ["0"]
# count: "all"
capabilities: ["gpu"]
${PWD}/model_repository 就是模型仓库的位置
使用 docker-compose 的命令启动即可
docker-compose up -d
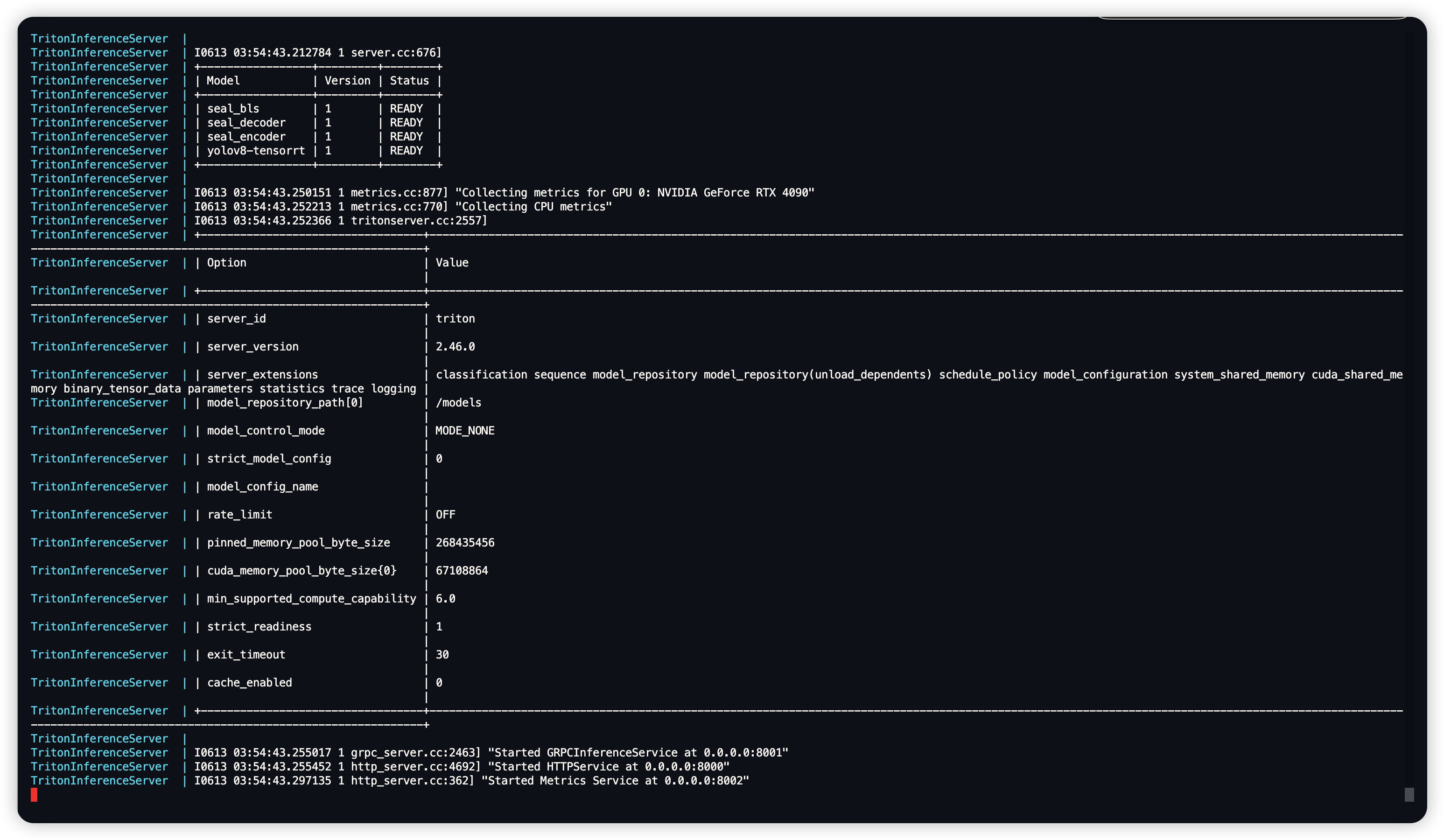
triton 部署 YOLOV8 (ONNX/TensorRT)
模型导出
我们训练完成的模型是 pt 格式的,Triton 支持 ONNX、PyTorch TorchScript 等格式,我们需要使用官方的导出函数来进行模型的导出。
官方文档:导出 -Ultralytics YOLO 文档
这里我们将模型转为 ONNX 格式,代码如下:
from ultralytics import YOLO
model = YOLO("best.pt")
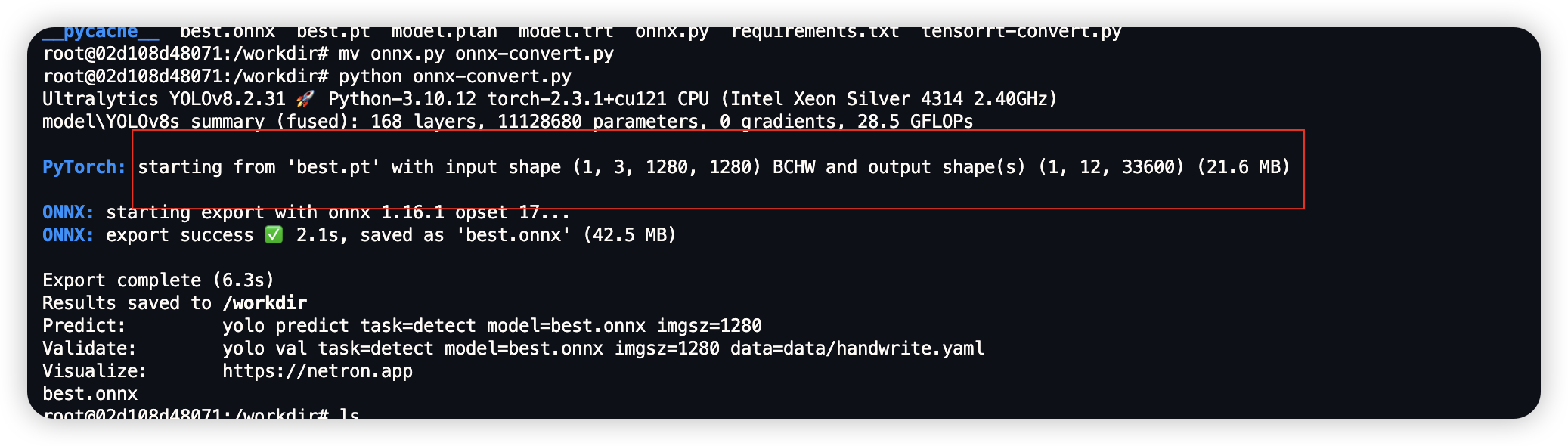
success = model.export(format="onnx", half=False, dynamic=True)
得到与输入模型同名但格式为 ONNX 格式的文件 best.onnx
且将模型导出时,YOLOv8 会将模型的输入输出张量也一并导出,请记录这些值。
模型仓库搭建
如上节所示,Triton 的模型仓库由模型配置文件、模型版本目录、模型文件等组成,我们根据给出的模型仓库结构对模型进行定义。
└── yolov8
├── 1
│ └── model.onnx
└── config.pbtxt
配置文件:
name: "yolov8" # 模型名称,和你的文件夹一一对应
platform: "onnxruntime_onnx" # 指定模型运行的后端
max_batch_size: 0 # 最大的批次大小,0代表自动
input [
# Triton Input输入对象配置
{
name: "images", # 输入名称(不要动,v8的模型定义就是这个)
data_type: TYPE_FP32, # 根据你的权重类型进行修改,这里我的模型时FP32
dims: [ 1,3,-1,-1 ] # 输入为1批次,自适应图片尺寸
}
]
output[
# Triton Output输出对象配置
{
name: "output0", # 输出名称
data_type: TYPE_FP32 # 输出数据类型
dims: [ 1,12,33600 ] # 输出大小,一般默认是1批次,N个类,8400个目标(当然比这个值小也正常)
# dims: [-1,-1,-1]
}
]
# 版本策略配置
# 其中latest代表Triton加载的最新版本模型
# num_version代表版本号
version_policy: { latest { num_versions: 1 } }
# instance_group:模型运行实例(设备)组配置
instance_group: [
{
count: 1 # 数量
kind: KIND_GPU # 类型
gpus: [ 0 ] # 如果参数项为GPU,则该列表将指定对应序号下的可见CUDA设备来运行模型
}
]
ONNX 与 TensorRT data_type 对照表
ONNX elem_type 数字 |
ONNX elem_type 描述 |
Triton data_type |
数据类型描述 |
|---|---|---|---|
| 1 | FLOAT |
TYPE_FP32 |
32 位浮点数 |
| 2 | UINT8 |
TYPE_UINT8 |
8 位无符号整数 |
| 3 | INT8 |
TYPE_INT8 |
8 位有符号整数 |
| 4 | UINT16 |
TYPE_UINT16 |
16 位无符号整数 |
| 5 | INT16 |
TYPE_INT16 |
16 位有符号整数 |
| 6 | INT32 |
TYPE_INT32 |
32 位有符号整数 |
| 7 | INT64 |
TYPE_INT64 |
64 位有符号整数 |
| 9 | BOOL |
TYPE_BOOL |
布尔值 |
| 10 | FLOAT16 |
TYPE_FP16 |
16 位浮点数 |
| 11 | DOUBLE |
TYPE_FP64 |
64 位浮点数 |
| 12 | UINT32 |
TYPE_UINT32 |
32 位无符号整数 |
| 13 | UINT64 |
TYPE_UINT64 |
64 位无符号整数 |
然后将该目录映射到 triton 的模型仓库下启动即可
模型转换为 TensorRT 部署
这里我们使用 TensorRT 的镜像将 ONNX 模型转为 TensorRT 模型。
官方镜像仓库:TensorRT | NVIDIA NGC
使用的版本: nvcr.io/nvidia/tensorrt:24.05-py3
转换代码官方 GitHub 仓库内有对 yolov5 的转换示例,我们通过借鉴该示例使用的函数来将模型转换为 TensorRT
转换代码为:
import tensorrt as trt
def build_engine(onnx_file_path, engine_file_path):
# 创建TensorRT logger对象
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# 创建builder和network
builder = trt.Builder(TRT_LOGGER)
runtime = trt.Runtime(TRT_LOGGER)
config = builder.create_builder_config()
profile = builder.create_optimization_profile()
flag = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
network = builder.create_network(flag)
# 创建ONNX解析器
parser = trt.OnnxParser(network, TRT_LOGGER)
# 解析ONNX模型
with open(onnx_file_path, 'rb') as onnx_file:
if not parser.parse(onnx_file.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
# 设置最大工作空间
# config.max_workspace_size = 1 << 30 # 1GB
# 选择模型的输入和输出格式,以及相关优化
# 如果你知道模型运行的最大批量大小,你可以在这里设置
# 例如: 如果你的模型输入尺寸是 CHW 的 (3, 224, 224) 并且最大批量大小是 8
# 我们自己训练的是1280
input_name = network.get_input(0).name
profile.set_shape(input_name, min=(1, 3, 640, 640), opt=(4, 3, 1280, 1280), max=(8, 3, 1280, 1280))
config.add_optimization_profile(profile)
# 根据配置构建引擎
plan = builder.build_serialized_network(network, config)
# engine = runtime.deserialize_cuda_engine(plan)
# 序列化引擎并保存到文件
with open(engine_file_path, 'wb') as engine_file:
engine_file.write(plan)
return plan
# ONNX模型和TensorRT引擎文件的路径
onnx_model_path = 'best.onnx'
tensorrt_engine_path = 'model.plan'
# 构建并保存TensorRT引擎
engine = build_engine(onnx_model_path, tensorrt_engine_path)
if engine:
print("ONNX model has been successfully converted to TensorRT engine and saved to", tensorrt_engine_path)
执行后获得 model.plan 格式模型,这个就是 TensorRT 模型了。
通过修改上一步模型仓库的配置文件,并启动就可以无缝切换部署
name: "yolov8" # 模型名称,和你的文件夹一一对应
platform: "tensorrt_plan" # 切换为TensorRT平台
max_batch_size: 0 # 最大的批次大小,0代表自动
input [
# Triton Input输入对象配置
{
name: "images", # 输入名称(不要动,v8的模型定义就是这个)
data_type: TYPE_FP32, # 根据你的权重类型进行修改,这里我的模型时FP32
dims: [ 1,3,-1,-1 ] # 输入为1批次,自适应图片尺寸
}
]
output[
# Triton Output输出对象配置
{
name: "output0", # 输出名称
data_type: TYPE_FP32 # 输出数据类型
dims: [ 1,12,33600 ] # 输出大小,一般默认是1批次,N个类,8400个目标(当然比这个值小也正常)
# dims: [-1,-1,-1]
}
]
# 版本策略配置
# 其中latest代表Triton加载的最新版本模型
# num_version代表版本号
version_policy: { latest { num_versions: 1 } }
# instance_group:模型运行实例(设备)组配置
instance_group: [
{
count: 1 # 数量
kind: KIND_GPU # 类型
gpus: [ 0 ] # 如果参数项为GPU,则该列表将指定对应序号下的可见CUDA设备来运行模型
}
]
查看 ONNX 模型和 PyTorch 模型的输入和输出张量
ONNX 和 PyTorch 都有官方的 API 来帮助我们实现这一目的,以下将分别列出函数。
- ONNX
import onnx
def get_onnx_model_info(onnx_model_path):
model = onnx.load(onnx_model_path)
# 获取输入信息
input_shape = {}
for input in model.graph.input:
shape = [dim.dim_value for dim in input.type.tensor_type.shape.dim]
i
nput_shape[input.name] = {'shape': shape, 'type': input.type.tensor_type.elem_type}
# 获取输出信息
output_info = {}
for output in model.graph.output:
shape = [dim.dim_value for dim in output.type.tensor_type.shape.dim]
output_info[output.name] = {'shape': shape, 'type': output.type.tensor_type.elem_type}
return input_shape, output_info
# 替换ONNX模型路径
onnx_model_path = 'encoder_model.onnx'
input_shape, output_info = get_onnx_model_info(onnx_model_path)
print("Input shape:", input_shape)
print("Output info:", output_info)
- PyTorch
import torch
import torch.nn as nn
def get_pytorch_model_info(model, example_input):
model.eval()
# 使用钩子来捕获输入和输出
input_info = {}
output_info = {}
def forward_hook(module, input, output):
input_info[module] = input[0].shape
output_info[module] = output.shape
hooks = []
for layer in model.modules():
if not isinstance(layer, nn.Sequential) and \
not isinstance(layer, nn.ModuleList) and \
layer != model:
hooks.append(layer.register_forward_hook(forward_hook))
with torch.no_grad():
model(example_input)
for hook in hooks:
hook.remove()
return input_info, output_info
# 示例PyTorch模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.fc1 = nn.Linear(16 * 30 * 30, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
return x
# 实例化模型并创建示例输入
model = SimpleModel()
example_input = torch.randn(1, 3, 32, 32)
# 获取模型的输入和输出信息
input_info, output_info = get_pytorch_model_info(model, example_input)
print("Input info:", input_info)
print("Output info:", output_info)
评论区